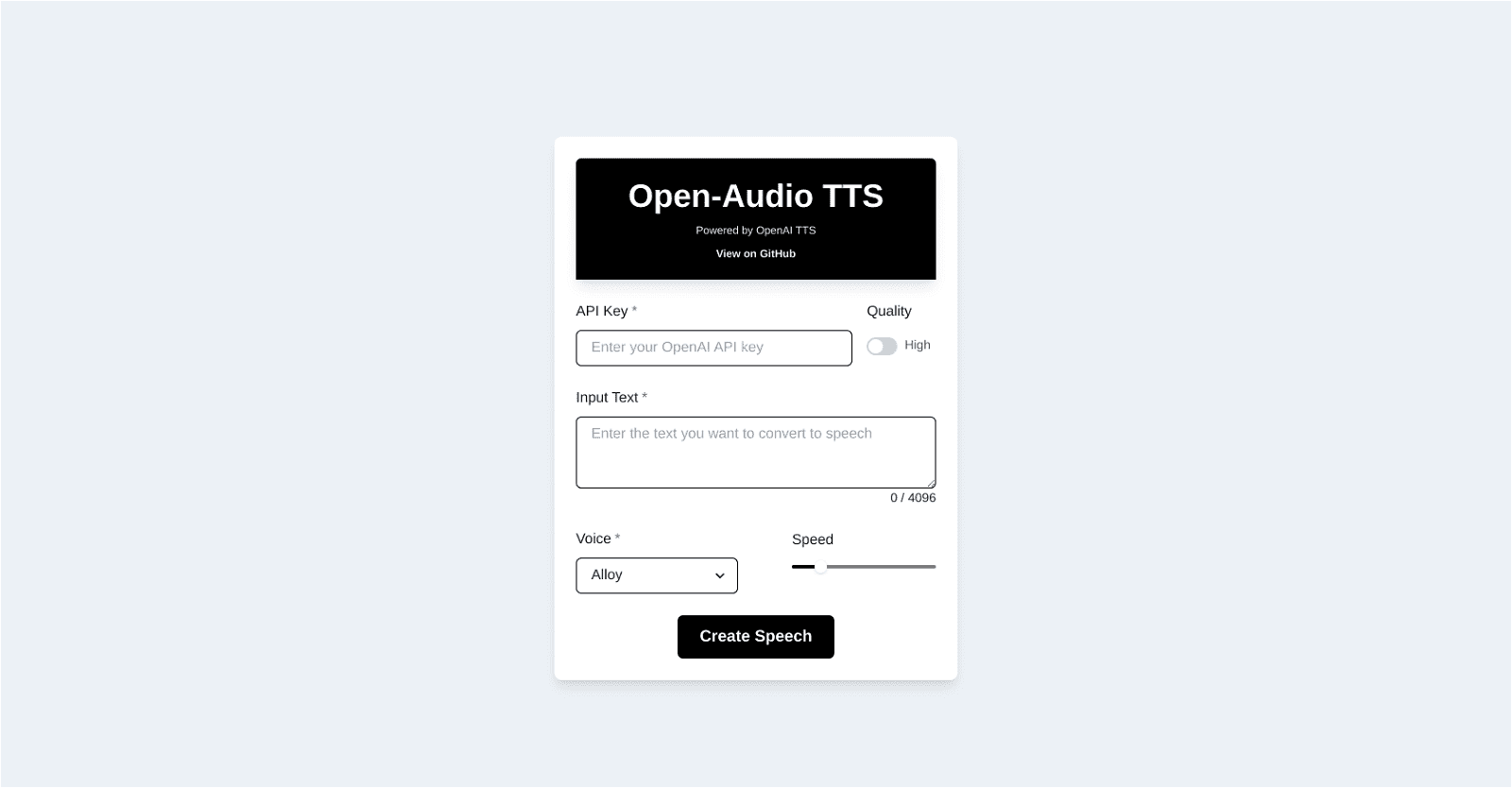
Open-Audio TTS leverages OpenAI’s technology to offer a versatile Text-to-Speech solution. Its core function is to swiftly and efficiently convert written text into spoken words.
This tool proves invaluable for users seeking a seamless transformation of written content into audio format. With a range of selectable voice types such as Alloy, Echo, Fable, Onyx, Nova, Shimmer, and more, it caters to diverse audio needs.
Furthermore, users have the flexibility to control the speech speed, enabling customization for desired audio effects. Open-Audio TTS finds application in various scenarios including podcast content creation, audiobook generation, aiding visually impaired individuals, and more, where text-to-audio conversion is essential.
Its versatility extends to the type of text it can handle, ensuring broad usability. It’s important for users to acquire an API Key to access Open-Audio TTS, which can be obtained freely via the Github platform where the tool is continuously updated and maintained.