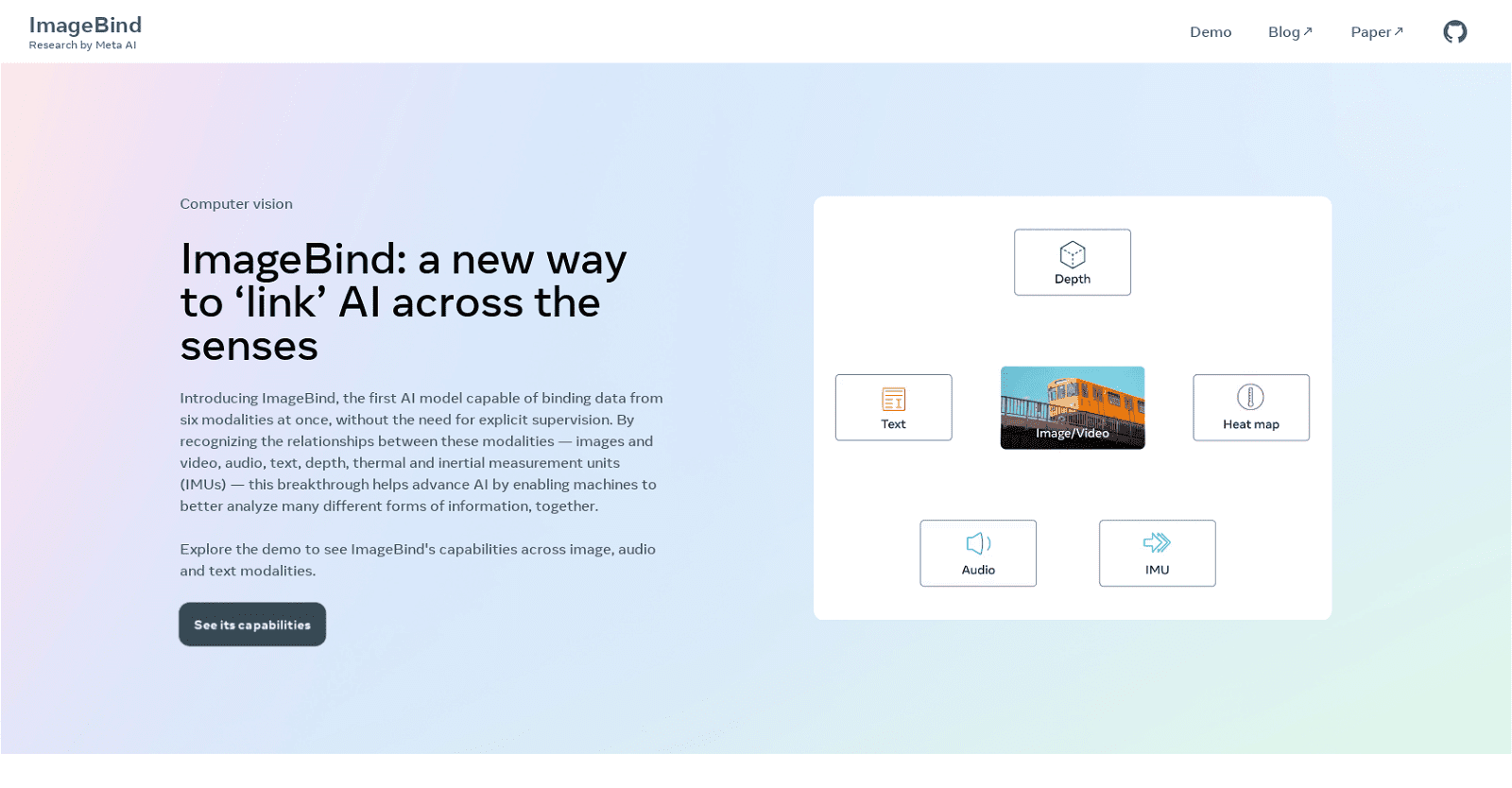
ImageBind, a revolutionary AI model developed by Meta AI, pioneers the binding of data from six modalities simultaneously, including images and video, audio, text, depth, thermal, and inertial measurement units (IMUs). This groundbreaking advancement enables machines to collectively analyze diverse information types by recognizing intermodal relationships, setting a new standard in unsupervised learning. By acquiring a unified embedding space that harmonizes multiple sensory inputs, ImageBind empowers existing AI models to seamlessly accommodate any of the six modalities, facilitating audio-based search, cross-modal search, multimodal arithmetic, and cross-modal generation.
Unlike previous specialized models trained explicitly for individual modalities, ImageBind excels in upgrading existing AI models to manage multifaceted sensory inputs, thereby enhancing recognition performance in zero-shot and few-shot recognition tasks across modalities. The ImageBind team has generously made the model open source under the MIT license, enabling global developers to leverage and integrate it into their applications while adhering to licensing regulations. Ultimately, ImageBind stands poised to propel machine learning capabilities forward by fostering collaborative analysis across various forms of information.
More details about ImageBind by Meta
Can ImageBind enhance the capability of other AI models?
Yes, ImageBind can enhance the capability of other AI models. It upgrades existing AI models to support input from any of the six modalities, which in turn boosts their recognition performance on zero-shot and few-shot recognition tasks across modalities.
What are the six modalities that ImageBind can bind at once?
The six modalities that ImageBind can bind at once are images and video, audio, text, depth, thermal, and inertial measurement units (IMUs).
What are the licensing terms for ImageBind?
The licensing terms for ImageBind fall under the MIT license, which allows developers worldwide to freely use and integrate the model into their applications as long as they comply with the license.
What is meant by explicit supervision and how does ImageBind achieve its tasks without it?
Explicit supervision refers to the manual human intervention required to train an AI model, guiding it towards expected outputs for given inputs. ImageBind, however, achieves its tasks without explicit supervision, meaning it has learned to process and relate data from different modalities without needing specific instruction to do so.