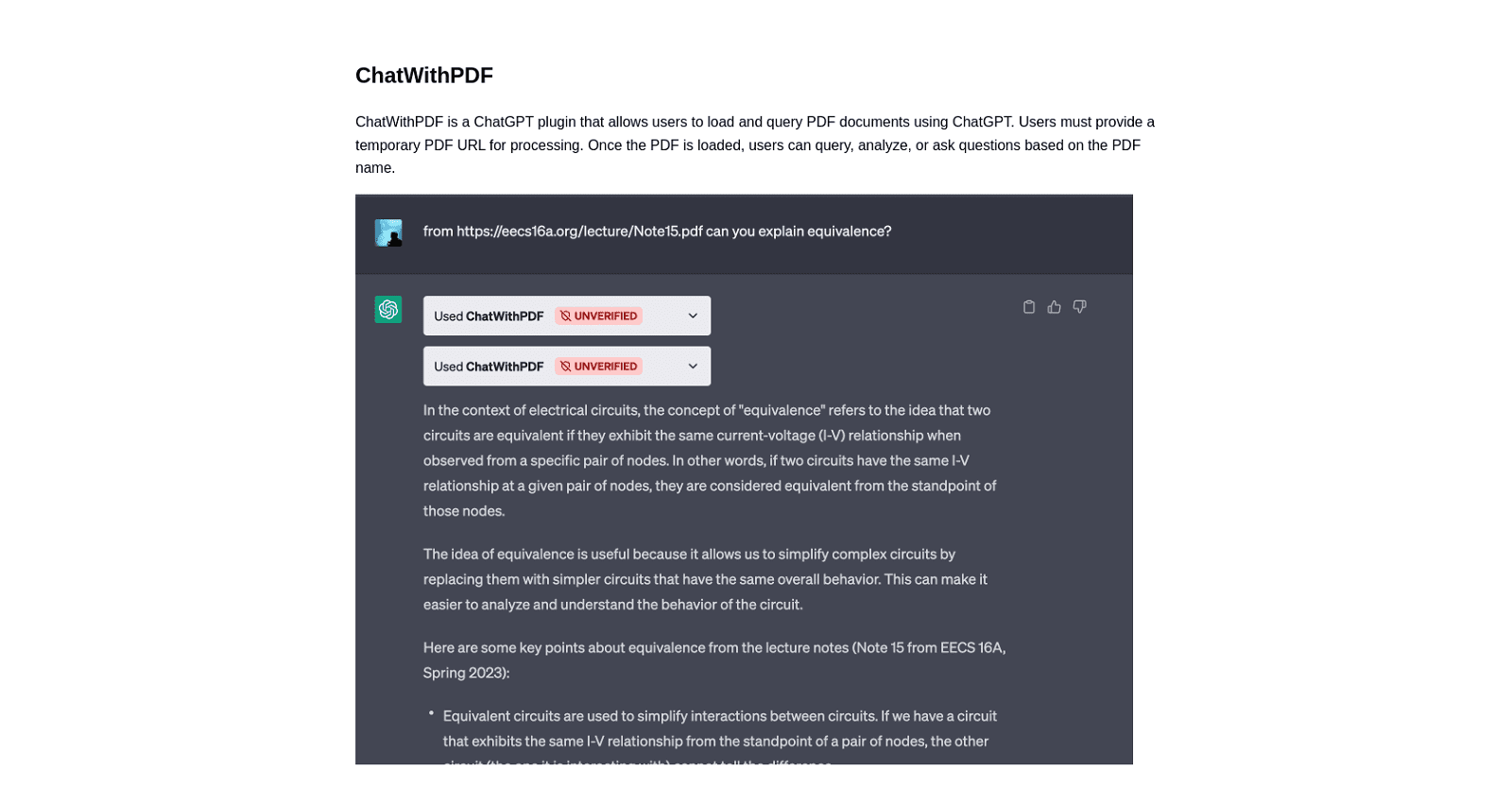
Chatwithpdf is a ChatGPT plugin tool designed to facilitate seamless interaction with PDF documents using ChatGPT. Users can load and query PDF documents by providing temporary URLs, enabling them to analyze, ask questions, and retrieve relevant information based on the content of the PDF.
This tool offers a convenient way to semantically search PDF documents, returning matches that are most relevant to user queries. By processing the PDF content and matching it with user queries, Chatwithpdf aims to provide accurate and appropriate results.
To use Chatwithpdf, users simply need to add it as an unverified plugin in the “Plugin Store” of the ChatGPT UI. As it is a web-based tool, there is no installation required, and it is readily available for immediate use.
Chatwithpdf prioritizes user privacy by not storing any data permanently. PDFs are embedded and immediately wiped after processing. Embeddings are stored with ChromaDB on the same deployment server and wiped with each new deployment.
Key features of Chatwithpdf include processing and semantically searching PDF documents, extracting relevant information based on user queries, and loading and processing PDF documents from temporary URLs.
Overall, Chatwithpdf is a valuable tool for users who need to efficiently extract information from PDF documents and desire a seamless user experience.
More details about ChatWithPDF
How do I load a PDF onto ChatWithPDF?
To load a PDF onto ChatWithPDF, you simply need to provide a temporary URL for the PDF document. The plugin fetches the PDF from the provided source for processing and querying.
In what format does ChatWithPDF return the query matches?
ChatWithPDF returns the query matches to users in an intuitive and conversational format. The most relevant matches, based on the user’s search input, are displayed in a user-friendly manner.
How does ChatWithPDF handle privacy and data storage?
ChatWithPDF prioritizes user privacy by not intentionally storing any data permanently. Upon completion of processing, the tool immediately wipes the embedded PDF. Any embeddings created are kept with ChromaDB on the same deployment server and are wiped with each new deployment.
What happens to the data in the PDF after a new deployment?
After a new deployment, all previously held embeddings from the PDFs are wiped from the deployment server. This practice ensures that user data is not retained beyond the duration necessary for processing and querying, aligning with ChatWithPDF’s commitment to privacy and data security.