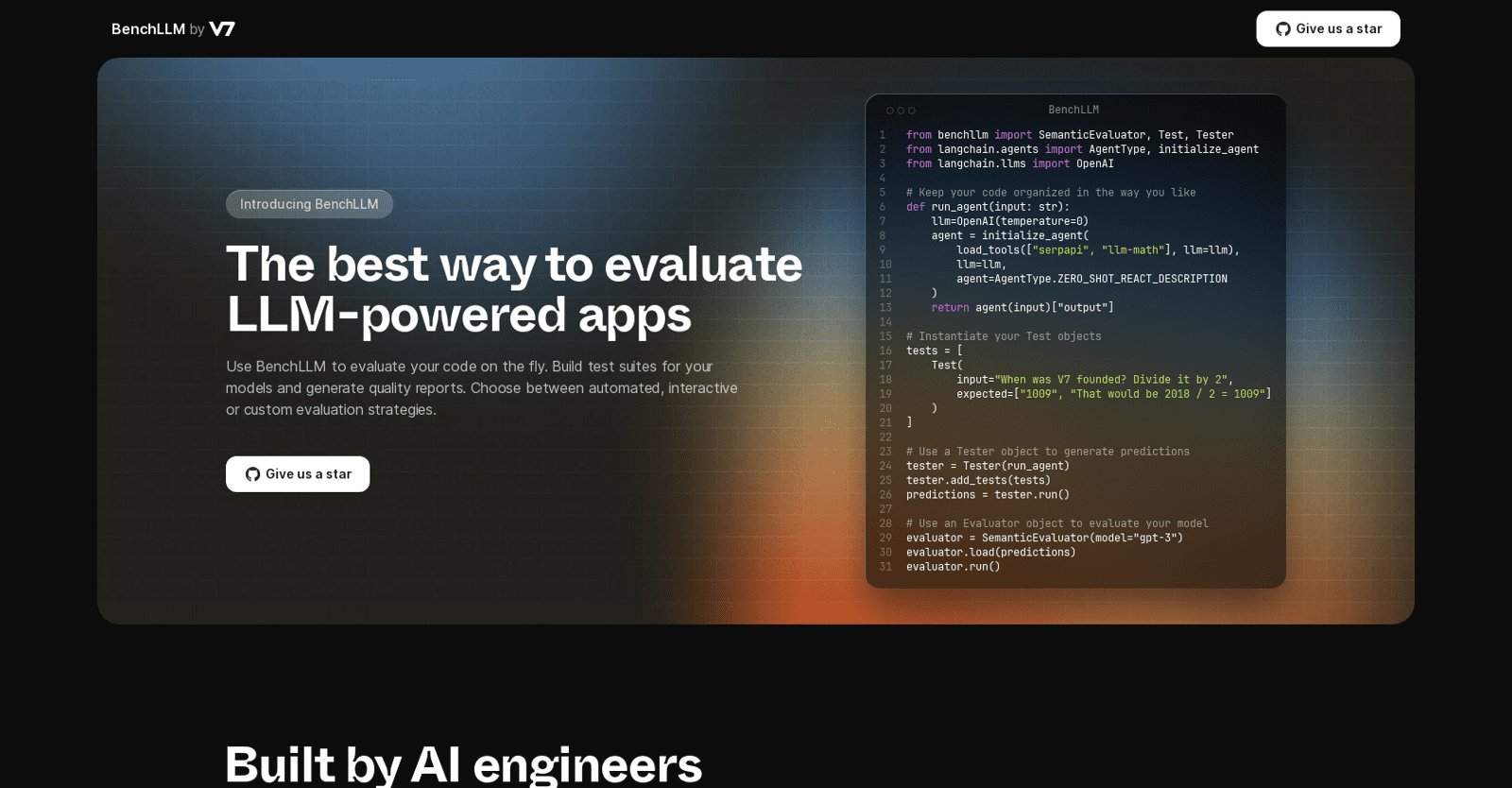
BenchLLM is a comprehensive evaluation tool tailored for AI engineers, empowering them to assess their machine learning models (LLMs) in real-time. Offering a range of evaluation strategies—automated, interactive, or custom—users can select the approach that best suits their needs. Flexibility is key, allowing engineers to structure their code according to their preferences.
The tool seamlessly integrates with various AI utilities like “serpapi” and “llm-math,” and includes an adjustable “OpenAI” feature, enabling users to fine-tune temperature parameters for optimal results. The evaluation process involves creating Test objects, defining specific inputs and expected outputs for the LLM. These tests are then bundled into a Tester object, which generates predictions based on the provided input. These predictions are subsequently fed into an Evaluator object, which utilizes the SemanticEvaluator model “gpt-3” to gauge the LLM’s performance.
Through running the Evaluator, engineers can obtain insights into their model’s accuracy and effectiveness. Developed by a team of dedicated AI engineers, BenchLLM aims to fulfill the longstanding need for an open and adaptable LLM evaluation tool. Emphasizing both the power and flexibility of AI, the creators prioritize reliability and predictability in results.
In essence, BenchLLM offers AI engineers a user-friendly and customizable platform to evaluate their LLM-powered applications comprehensively. From constructing test suites to generating quality reports and assessing model performance, BenchLLM caters to the diverse needs of AI developers, aiming to become the benchmark tool they’ve long awaited.
More details about BenchLLM
Why was BenchLLM created?
A group of AI engineers developed BenchLLM in response to the demand for an adaptable and open-source LLM assessment tool. The designers aimed to produce predictable, dependable outcomes while striking a balance between AI’s strength and adaptability.
Can BenchLLM be used in a CI/CD pipeline?
It is possible to use BenchLLM in a CI/CD workflow. You may utilize the CLI as a testing tool in your CI/CD workflow because it functions with straightforward and elegant CLI commands.
How does BenchLLM generate evaluation reports?
By applying the Evaluator to the LLM’s predictions, BenchLLM produces evaluation reports. The report offers specifics regarding the model’s correctness and performance in relation to the anticipated results.
What formats does BenchLLM support to define tests?
JSON or YAML test definition formats are supported by BenchLLM. This allows you to define tests in a format that is appropriate and simple to comprehend.