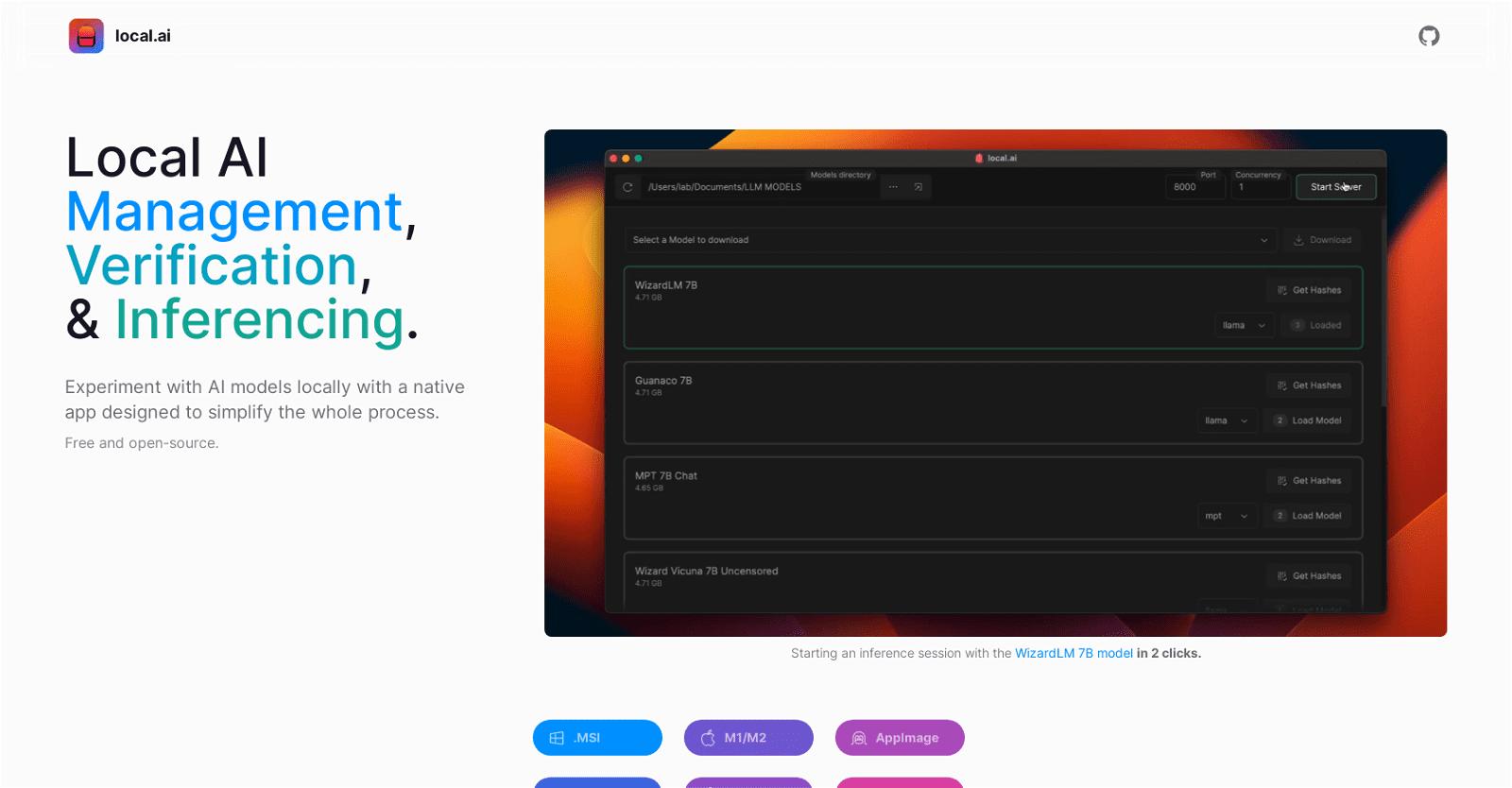
The Local AI Playground is a user-friendly native app designed to simplify AI experimentation without the need for technical setup or a dedicated GPU. It’s free, open-source, and boasts a memory-efficient Rust backend, making it compact and suitable for various computing environments.
With CPU inferencing capabilities and adaptable thread usage, it accommodates different computing setups. Additionally, it supports GGML quantization with multiple options, enhancing flexibility.
This tool excels in model management, offering centralized tracking of AI models. It features resumable, concurrent model downloading, usage-based sorting, and directory structure agnosticism.
To ensure model integrity, it employs robust digest verification using BLAKE3 and SHA256 algorithms, including digest computation, known-good model API, and license and usage chips.
Moreover, it includes an inferencing server feature for local streaming, with a user-friendly UI, .mdx file writing support, and inference parameter options.
Overall, the Local AI Playground provides an efficient environment for local AI experimentation, model management, and inferencing, enhancing accessibility and usability for users.
More details about Local AI
Is Local AI open-source and where can I get the source code?
Yes, Local AI is indeed open-source, and you can access its source code from its GitHub page.
Does Localaoffer a GPU inferencing feature?
At present, Local AI provides CPU inferencing capabilities. However, GPU inferencing is listed as an upcoming feature, indicating that it will be available in the future.
What is the function of the inferencing server feature?
The inferencing server feature in Local AI simplifies the process of conducting AI experiments by enabling users to initiate a local streaming server dedicated to AI inferencing. This functionality facilitates the execution of experiments and the retrieval of results with ease.
What are the main features of Local AI?
Local AI presents a range of essential features: CPU inferencing, which adjusts to available threads; GGML quantization with choices for q4, 5.1, 8, and f16; model management including resumable and concurrent downloading, and usage-based sorting; robust digest verification utilizing BLAKE3 and SHA256 algorithms alongside a known-good model API, license, and usage chips; an inferencing server feature for AI inferencing featuring a quick inference UI, writing support to .mdx files, and customizable inference parameters and remote vocabulary options.