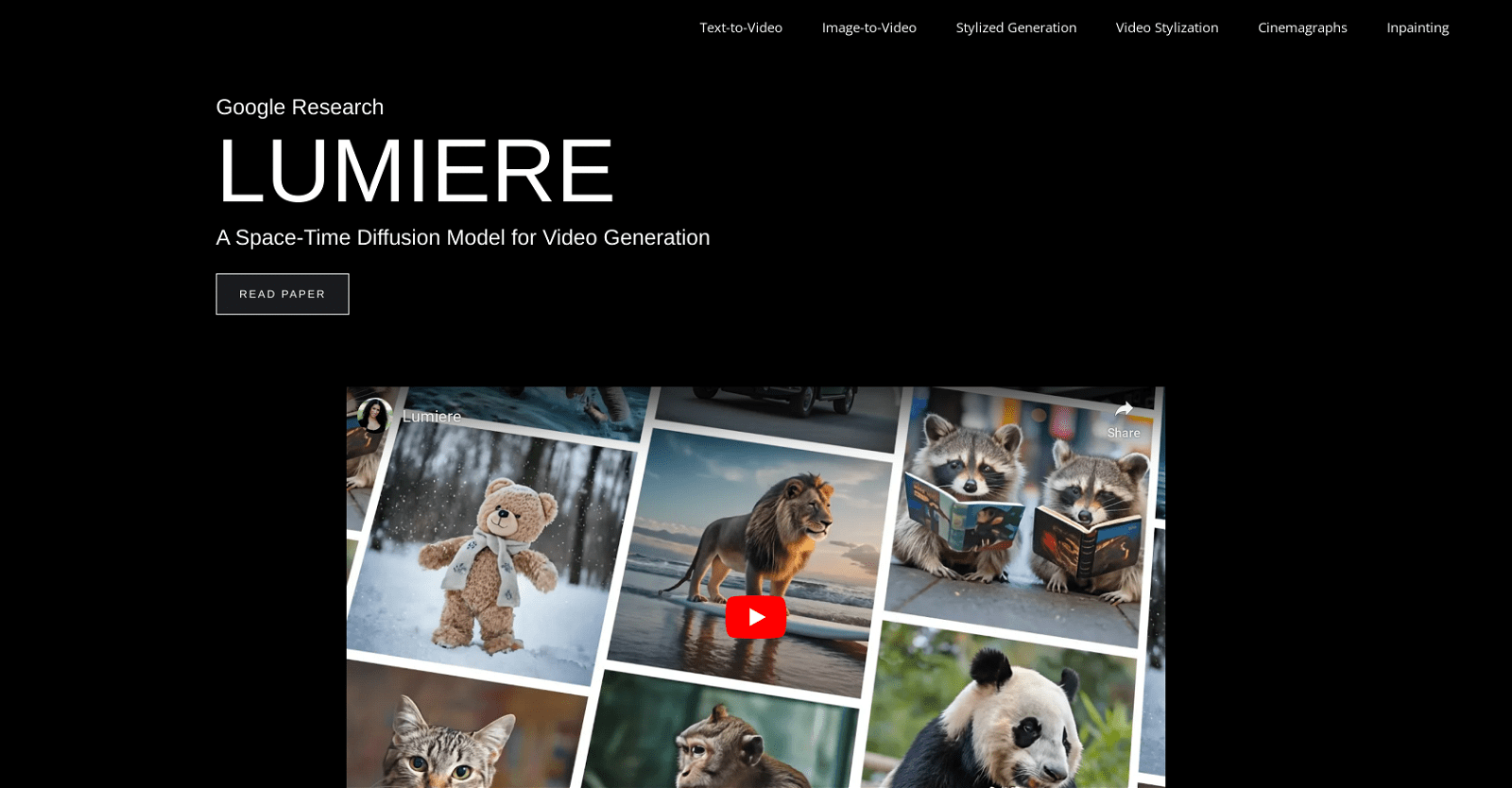
Developed by Google Research, Lumiere stands at the forefront as a cutting-edge space-time diffusion model meticulously crafted for video generation. Lumiere’s primary objective revolves around synthesizing videos that exhibit realism, diversity, and coherence in motion.
Comprising three distinct functionalities, Lumiere offers Text-to-Video, Image-to-Video, and Stylized Generation features. Through Text-to-Video, Lumiere dynamically interprets text inputs or prompts to generate captivating videos.
Similarly, the Image-to-Video feature utilizes an input image as a starting point for video generation. Lumiere’s Stylized Generation capability further enhances videos by infusing them with unique styles derived from a single reference image.
What sets Lumiere apart is its employment of a distinct Space-Time U-Net architecture, enabling it to generate entire videos in a single pass. This approach differs from many existing video models, which typically create keyframes before performing temporal super-resolution, potentially compromising the video’s temporal consistency.
Lumiere’s versatility extends across various scenes and subjects, including animals, nature scenes, objects, and people, often portraying them in novel or fantastical situations.
With potential applications spanning entertainment, gaming, virtual reality, advertising, and beyond, Lumiere serves as a powerful tool wherever dynamic and responsive visual content is essential.
More details about Lumiere
How does Lumiere bring images to life?
Lumiere utilizes its cinemagraph feature to animate specific sections within a single image, while keeping the rest static. By defining the desired animated region through a mask, Lumiere applies motion solely to that area in the resulting video.
What is the role of Lumiere’s Space-Time diffusion model?
Lumiere’s Space-Time diffusion model aims to craft videos with realistic, varied, and coherent motion. This model specializes in generating videos from text or image inputs and infusing them with a distinctive style derived from a single reference image, thus delivering dynamic and evocative visual content.
How does Lumiere employ a single reference image for Stylized Generation?
In Lumiere’s Stylized Generation feature, a single reference image serves as the blueprint for the video’s overall aesthetic. By analyzing the artistic elements of the reference image, Lumiere replicates and applies these attributes throughout the video, ensuring a cohesive style consistent with the reference image.
What is Lumiere’s Text-to-Video feature and how does it function?
Lumiere’s Text-to-Video feature crafts videos based on provided text inputs or prompts. These textual cues serve as the foundation for the video’s narrative or content, with Lumiere dynamically translating the text into a captivating visual representation.