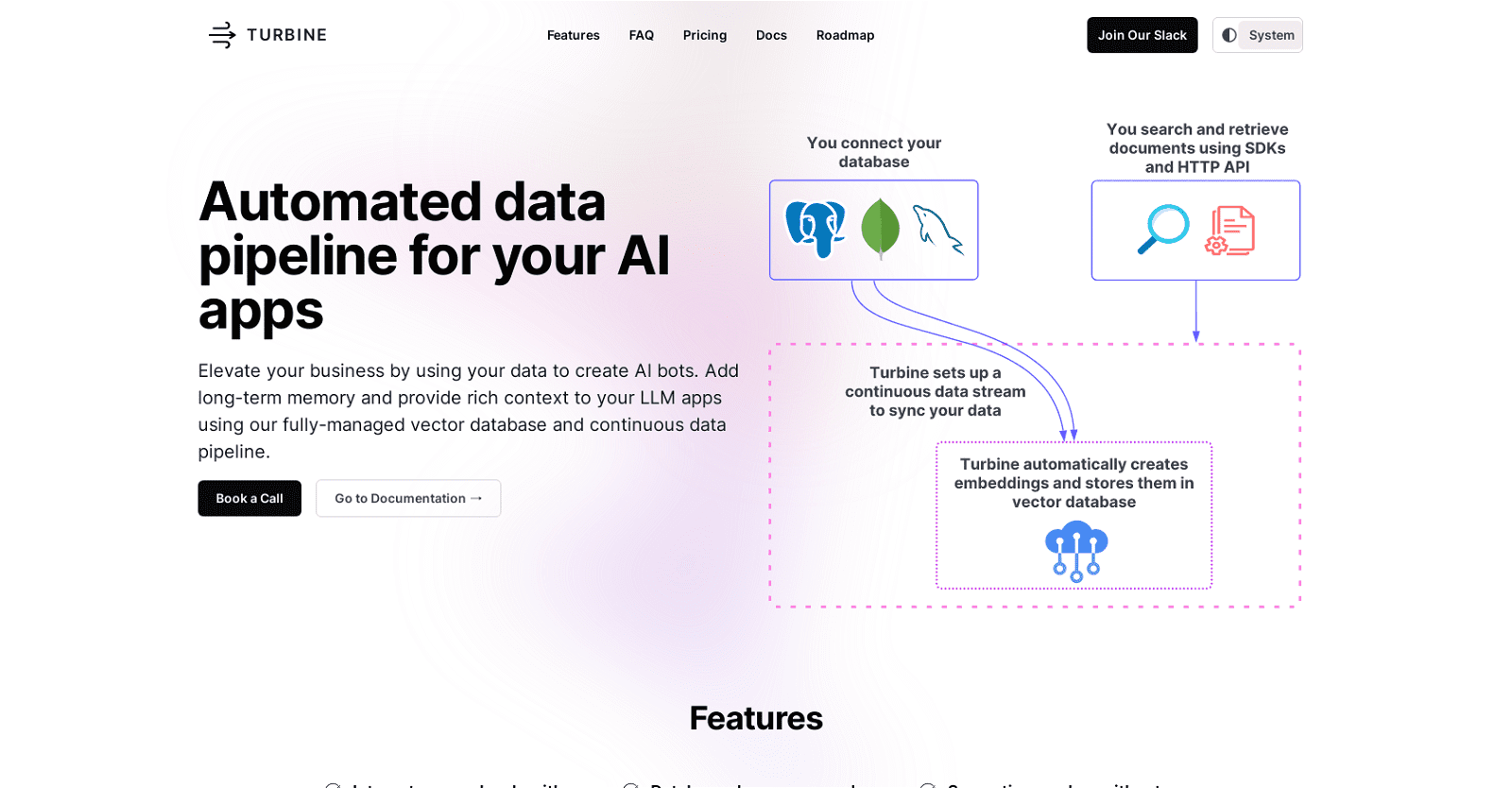
Turbine is an automated data pipeline tool specifically crafted to bolster AI applications. Acting as a vector search engine, it streamlines the synchronization of data from diverse databases and readies it for vector searches, ensuring seamless integration with AI bots while alleviating concerns about infrastructure management.
This tool presents several pivotal features to its users. Firstly, it seamlessly integrates with prevalent databases like PostgreSQL, MongoDB, and MySQL, with future integrations in the pipeline. The real-time synchronization of database changes eliminates the necessity for batch jobs, ensuring that searches are always up-to-date. Moreover, Turbine supports the storage of embeddings through leading vector databases such as Pinecone and Milvus, accommodating various embedding models from smaller ones like MiniLM-L6-V2 to cutting-edge OpenAI models.
Turbine simplifies the onboarding process with its Python and TypeScript SDKs, alongside an HTTP API for added flexibility. Its high level of configurability empowers users to optimize different aspects, including the choice of embedding model, data filters, and included fields. Integration with LangChain AI bots is effortlessly achieved with just a few lines of code.
Designed for scalability, Turbine leverages modern distributed stream-processing platforms to efficiently handle data. Its streamlined design and robust functionality enable users to develop AI applications capable of delivering accurate and context-rich results, leveraging the prowess of language models and searchable databases to the fullest extent.