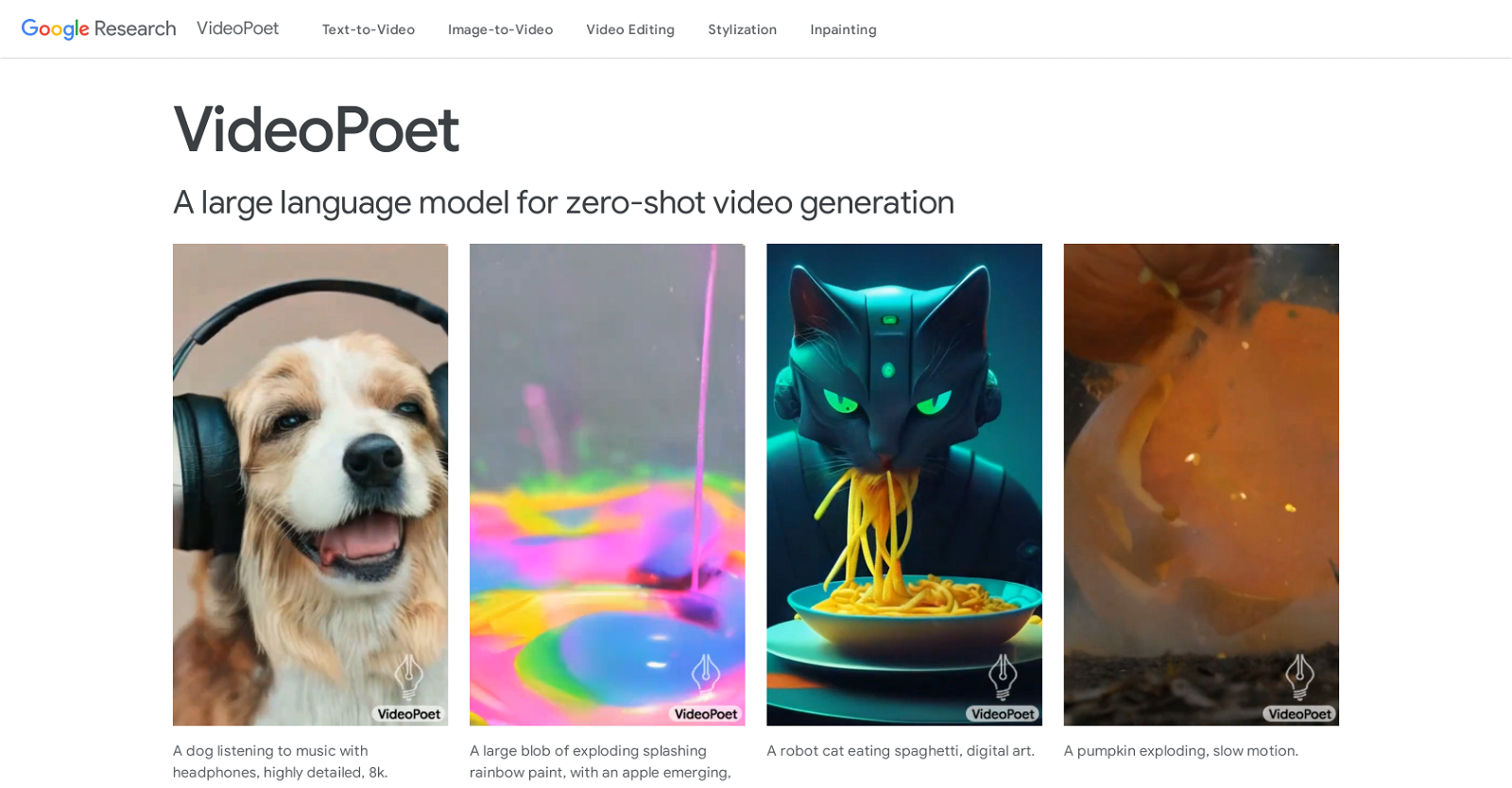
VideoPoet, developed by Google Research, marks a significant advancement in video generation, particularly in creating large-scale, captivating, and high-fidelity motions.
This innovative tool transforms autoregressive language models into powerful video generators. It incorporates specialized components like MAGVIT V2 video tokenizer and SoundStream audio tokenizer, which efficiently convert images, videos, and audio clips of varying lengths into a sequence of discrete codes within a unified vocabulary.
These codes are then aligned with text-based language models, enabling seamless integration with other modalities such as text. Within VideoPoet, an autoregressive language model learns across multiple modalities—video, image, audio, and text—to predict the next video or audio token in the sequence.
Moreover, VideoPoet integrates diverse multimodal generative learning objectives into its training framework. These objectives include text-to-video, text-to-image, image-to-video, video frame continuation, video inpainting and outpainting, video stylization, and video-to-audio capabilities.
VideoPoet offers flexibility by generating videos in square or portrait orientation, catering to the needs of short-form content creators. Additionally, it supports audio generation from video inputs.
With its ability to multitask across various video-centric inputs and outputs, VideoPoet demonstrates how language models can synthesize and edit videos with remarkable temporal consistency.
More details about VideoPoet by Google
How is the autoregressive functionality used in VideoPoet?
The autoregressive functionality in VideoPoet learns across various modalities such as video, image, audio, and text to predict the next video or audio token in the sequence. This approach is crucial for synthesizing and editing videos with a high degree of temporal consistency.
What kind of languages does VideoPoet support?
While specific languages are not defined on their website, VideoPoet typically utilizes autoregressive language models capable of understanding and processing human languages, suggesting potential support for multi-language functionality.
Can VideoPoet generate both video and audio?
Yes, VideoPoet can generate both video and audio. Its integrated process allows for the generation of audio from a video input, ensuring synchronization of both audio and visual aspects in the resulting clip.
How does VideoPoet generate videos using language models?
VideoPoet generates videos by integrating autoregressive language models into the video generation process. It employs components like the MAGVIT V2 video tokenizer and SoundStream audio tokenizer to convert images, video, and audio clips into a sequence of discrete codes. These codes, combined with text-based language models, enable integration with other modalities such as text, facilitating the prediction of the next video or audio token in the sequence.